

I found this app: https://f-droid.org/en/packages/com.nfcarchiver.nfc_archiver/
This interested me as I like the idea of storing larger amount of digital data on unusual mediums, like Optar which was a program to store data on paper.
But in the end, when I checked its GitHub after finding some issues, I found this:
Anyway.
2 minor issues are that compressed size is only estimated, even though it will never work with more than a few MB at best (62.13MB).
Second, it also doesn’t tell you when the max size is exceeded at first, only when you try to make the archive. Additionally, the max size isn’t mentioned.
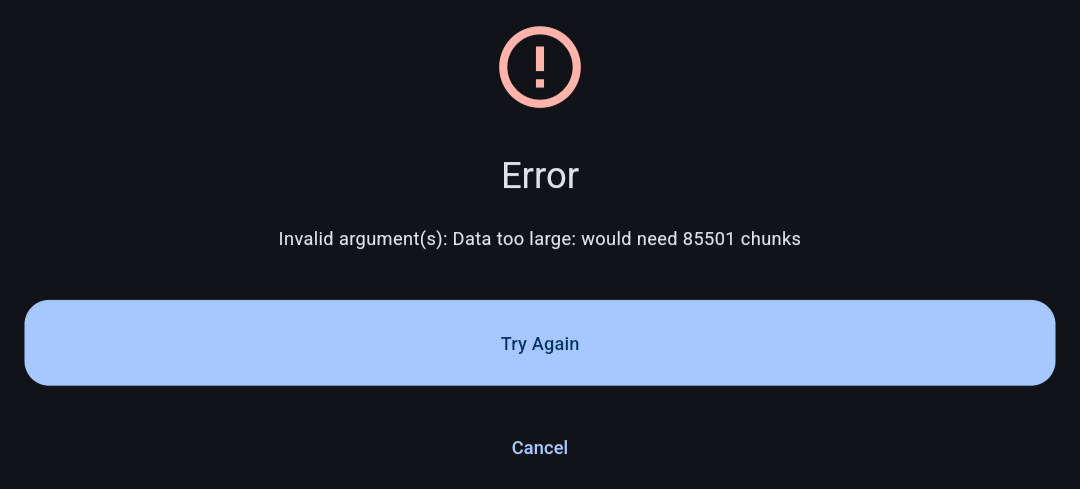
Based on the documentation, which is also partially incorrect, the limit is probably 216 chunks.
And now the main issue - fitting 76B into 48B of memory
I am just a random dumb person, so I may have made some mistakes too.
Anyway, I noticed that selecting the MIFARE Ultralight option does nothing in the app:
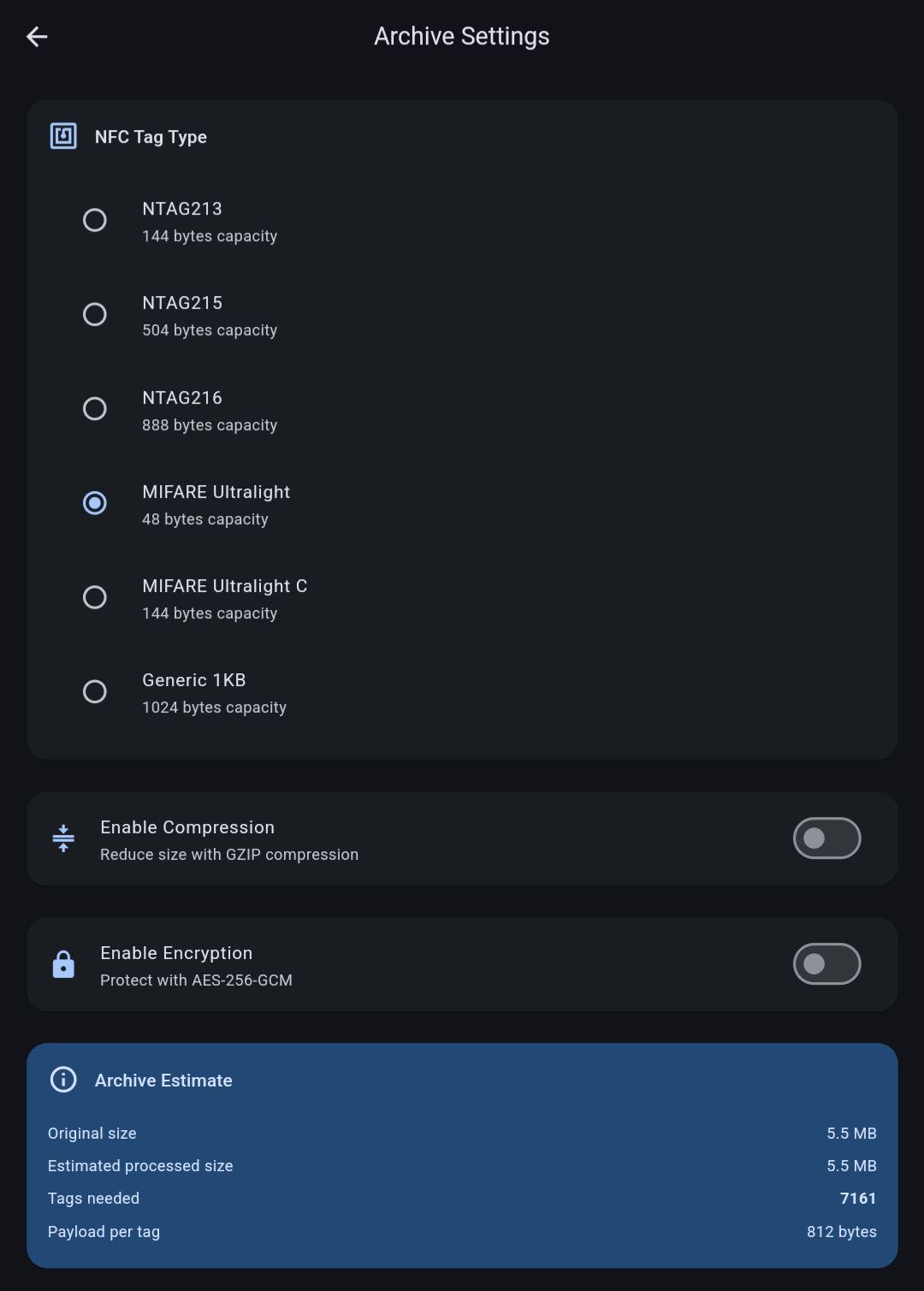
Notice how at the bottom data from previous option is kept.
But why?
This part of docs will be useful:

First of all, I find the format quite inefficient for something with so little storage.
1 whole byte for 2 bits of data? (compression/encryption flags)
Motherfucking 16 byte ID? (when the smallest “supported” medium is 48 bytes)
Notice how the documentation accounts for ~38 byte overhead (which already excluded the mentioned CRC).
Now, let’s open this file: https://github.com/mezinster/nfcarchiver/blob/master/lib/core/constants/nfar_format.dart
/// Header field sizes in bytes
abstract class NfarHeaderSize {
static const int magic = 4;
static const int version = 1;
static const int flags = 1;
static const int archiveId = 16;
static const int totalChunks = 2;
static const int chunkIndex = 2;
static const int payloadSize = 2;
static const int crc32 = 4;
/// Total header size (without payload)
static const int total = magic +
version +
flags +
archiveId +
totalChunks +
chunkIndex +
payloadSize +
crc32;
}
The total is 32.
Now for NDEF:
int get maxPayloadSize {
// NDEF overhead includes:
// - NDEF record header: 3-6 bytes (flags, type length, payload length)
// - MIME type: 33 bytes ("application/vnd.nfcarchiver.chunk")
// - NDEF TLV wrapper: ~5 bytes
// Total NDEF overhead: ~41-44 bytes
// We use 44 bytes as a safe margin
const ndefOverhead = 44;
final available = capacity - ndefOverhead;
return available - NfarHeaderSize.total;
}
So that’s statically defined as 44 bytes. Together, that’s 76 bytes. If you look at the earlier screenshot, having previously selected 888B tag, the usable size is shown as 812B. 888 - 812 = 76
So that checks out.
So, if the tag capacity is 48, we end up with -28. Negative available storage, nice.
At least this commit mentions the previous assumption of 10 bytes.
Also, there’s this bit:
/// Minimum supported tag capacity
static const int minTagCapacity = 64;
So if I understand this all correctly:
- Smallest “supported” tag type is 48B
- The code defines smallest supported size as 64B
- The format has a 76B overhead
What?
Oooh, that seems like a really good idea! I’d certainly make use of it
They can’t seem to make even a useful search function, I doubt they could pull an anti-ai tag off

