The advice, which is specifically for virtual machines using Azure, shows that sometimes the solution to a catastrophic failure is turn it off and on again. And again.
boot into safe mode, navigate to the affected file, and delete it.
Yeah. That’s the easiest, unless the drive is encrypted.
I imagine the folks going for the 15 reboots approach are doing so because it’s easier than waiting in line for their IT help desk to deliver them their boot encryption key.

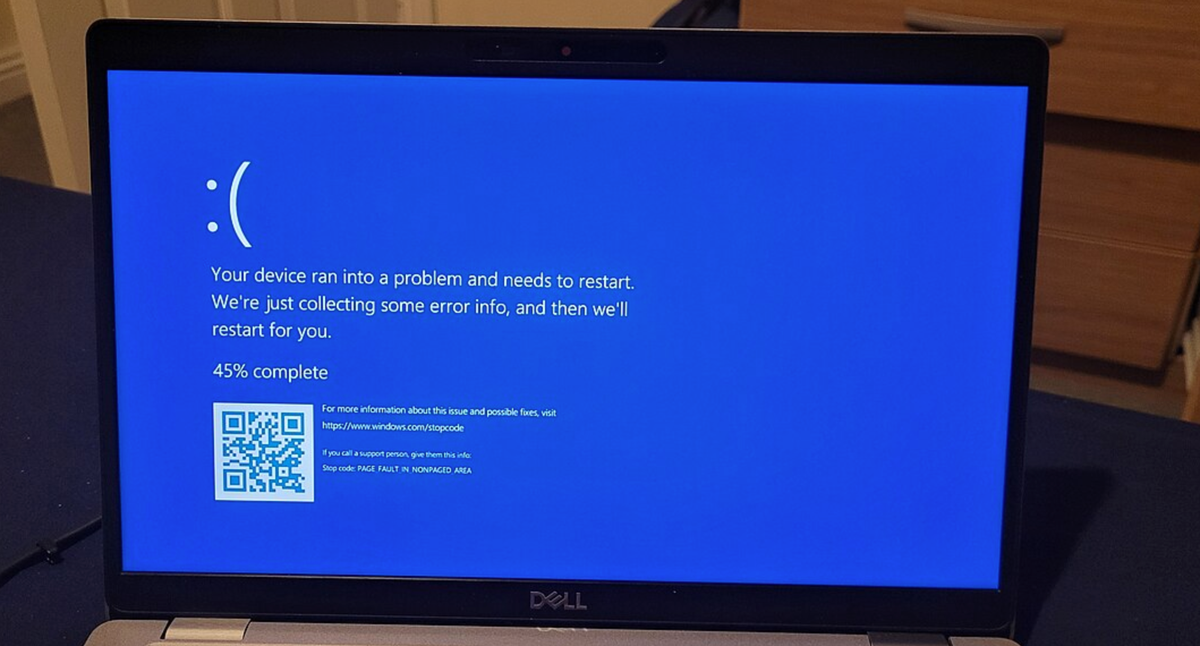
Is anyone able to read the full article? Is this a boot loop OS detection feature?
I saw in another thread: sometimes upon booting, the updater has just enough time to grab the fixed update before BSOD so keep trying.
I saw some SysAdmin threads as it was happening say to boot into safe mode, navigate to the affected file, and delete it.
Yeah. That’s the easiest, unless the drive is encrypted.
I imagine the folks going for the 15 reboots approach are doing so because it’s easier than waiting in line for their IT help desk to deliver them their boot encryption key.
Especially when the encryption keys are all stored on a Windows server that’s bootlooped
I haven’t been affected by this personally, just curious at this point what the variables are hah
Sounds like a race condition in a kernel driver. Try it enough times and maybe you can get clear of it once without triggering.
Archive.ph version
bless up thank you