
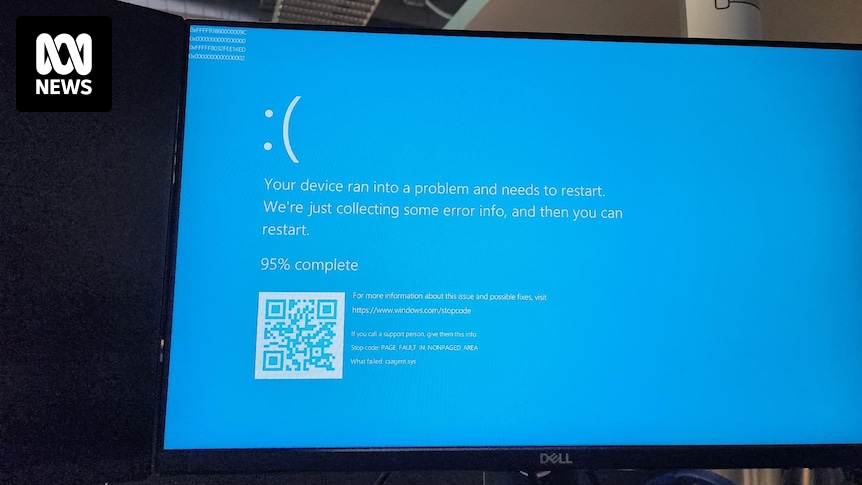
All our servers and company laptops went down at pretty much the same time. Laptops have been bootlooping to blue screen of death. It’s all very exciting, personally, as someone not responsible for fixing it.
Apparently caused by a bad CrowdStrike update.
Edit: now being told we (who almost all generally work from home) need to come into the office Monday as they can only apply the fix in-person. We’ll see if that changes over the weekend…
I think we’re defining disaster differently. This is a disaster. It’s just not one that necessitates restoring from backup.
Disaster recovery is about the plan(s), not necessarily specific actions. I would hope that companies recognize rerolling the server from backup isn’t the only option for every possible problem.
I imagine CrowdStrike pulled the update, but that would be a nightmare of epic dumbness if organizations got trapped in a loop.
I’ve not read a single DR document that says “research potential options”. DR stuff tends to go into play AFTER you’ve done the research that states the system is unrecoverable. You shouldn’t be rolling DR plans here in this case at all as it’s recoverable.
I also would imagine that they’d test updates before rolling them out. But we’re here… I honestly don’t know though. None of the systems under my control use it.
Right, “research potential options” is usually part of Crysis Management, which should precede any application of the DR procedures.
But there’s a wide range for the scope of those procedures, they might go from switching to secondary servers to a full rebuild from data backups on tape. In some cases they might be the best option even if the system is easily recoverable (eg: if the DR procedure is faster than the recovery options).
Just the ‘figuring out what the hell is going on’ phase can take several hours, if you can get the DR system up in less than that it’s certainly a good idea to roll it out. And if it turns out that you can fix the main system with a couple of lines of code that’s great, but noone should be getting chastised for switching the DR system on to keep the business going while the main machines are borked.
That’s a really astute observation - I threw out disaster recovery when I probably ought to have used crisis management instead. Imprecise on my part.
The other commenter on this pointed out that I should have said crisis management rather than disaster recovery, and they’re right - and so were you, but I wasn’t thinking about that this morning.
Nah, it’s fair enough. I’m not trying to start an argument about any of this. But ya gotta talk in terms that the insurance people talk in (because that’s what your c-suite understand it in). If you say DR… and didn’t actually DR… That can cause some auditing problems later. I unfortunately (or fortunately… I dunno) hold the C-suite position in a few companies. DR is a nasty word. Just like “security incident” is a VERY nasty phrase.