The AI crowd continue to mangle the meaning of words to make their unimpressive work sound “revolutionary”. This isn’t a “game engine”, this is just a model to create plausible video game frames given previous video game frames. A video auto-complete.
At no point in the paper do they mention any human inputs in their experimental setup. They just generate clips, plop it on MTurk and claim “they’re as good as the original.”
From the very beginning of their paper.
Computer games are manually crafted software systems centered around the following game loop: (1) gather user inputs, (2) update the game state, and (3) render it to screen pixels.
Their work neither gathers user input, nor does it keep a game state, it just renders pixels from pixels.
And there’s this noise:
Today, video games are programmed by humans. GameNGen is a proof-of-concept for one part of a new paradigm where games are weights of a neural model, not lines of code.
“It’s all matrix weights”
GameNGen shows that an architecture and model weights exist such that a neural model can effectively run a complex game (DOOM) interactively on existing hardware.
“Effectively run”
While many important questions remain, we are hopeful that this paradigm could have important benefits. For example, the development process for video games under this new paradigm might be less costly and more accessible, whereby games could be developed and edited via textual descriptions or examples images.
Prompt-based games. Thankfully it’ll be cheaper for the poor video game companies (Nvidia subscription fee not included).
Note how nothing that they proposed is even hinted at by their research. They don’t even make the code available, so none of their actual research is verifiable. They just fill their article with incomprehensible jargon about metrics and loss functions so that journalists will just assume they’re really smart and knew what they were doing in order to uncritically report on this.
I propose a better name for the work: “Diffusion Models Are Video Generators”.
Those actions described in that section are generated by an RL agent, used only for training. For the prediction and therefore results they still either check for aggregate metrics (which must use synthetic data in order to get enough of it), or do the MTurk comparison that generated up to 3 second clips which could in theory be created from real-time user input but since they have corresponding ground-truth frames it must at best be generated from sampled user input from a real gameplay session.
The clips they show on the YouTube video seem to have some interactive input, but the method for creating those is not described in the paper. So I suppose it is possible that there’s some degree of real time user input, but it’s not clear that it is in fact what’s happening there.
As a sidenote: ML researchers should really consider just dropping all the infodumping about their model architecture to an Appendix (or better yet, to runnable code) where they’ll clutter the article less and put in more effort into describing their experimental setups and scrutinizing results. I couldn’t care less about how they used ADAM to train a recurrent CNN on the Graph Laplacean if the experiments are junk or the results do not support the conclusions.
The human rater experiment (IMO the most important one for a human-interfacing software tool) is described from setup to a results in a single paragraph.


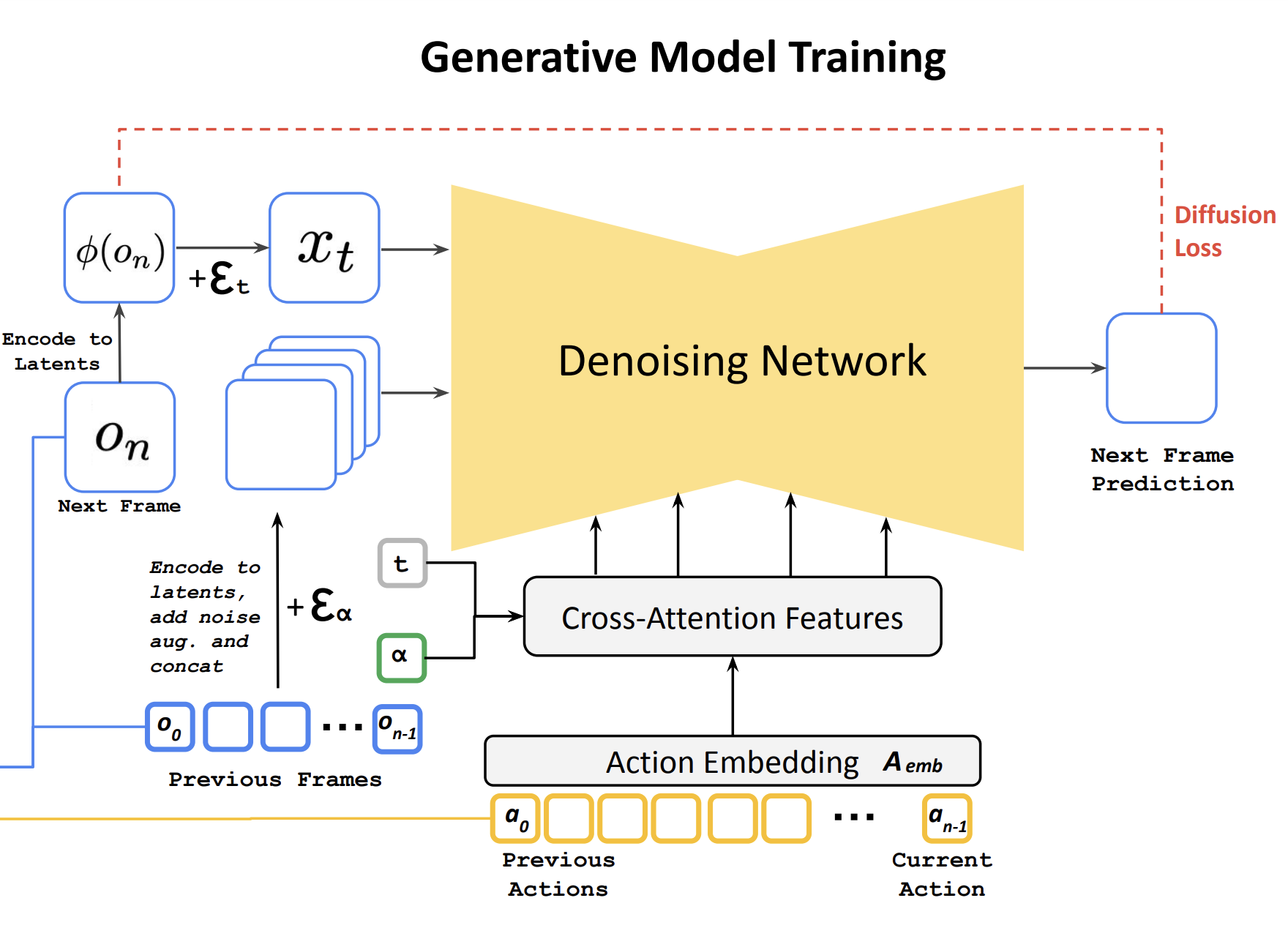
That’s dumb.
The AI crowd continue to mangle the meaning of words to make their unimpressive work sound “revolutionary”. This isn’t a “game engine”, this is just a model to create plausible video game frames given previous video game frames. A video auto-complete.
At no point in the paper do they mention any human inputs in their experimental setup. They just generate clips, plop it on MTurk and claim “they’re as good as the original.”
From the very beginning of their paper.
Their work neither gathers user input, nor does it keep a game state, it just renders pixels from pixels.
And there’s this noise:
“It’s all matrix weights”
“Effectively run”
Prompt-based games. Thankfully it’ll be cheaper for the poor video game companies (Nvidia subscription fee not included).
Note how nothing that they proposed is even hinted at by their research. They don’t even make the code available, so none of their actual research is verifiable. They just fill their article with incomprehensible jargon about metrics and loss functions so that journalists will just assume they’re really smart and knew what they were doing in order to uncritically report on this.
I propose a better name for the work: “Diffusion Models Are Video Generators”.
it does use user input “a diffusion model is trained to produce the next frame, conditioned on the sequence of past frames and actions.”
Those actions described in that section are generated by an RL agent, used only for training. For the prediction and therefore results they still either check for aggregate metrics (which must use synthetic data in order to get enough of it), or do the MTurk comparison that generated up to 3 second clips which could in theory be created from real-time user input but since they have corresponding ground-truth frames it must at best be generated from sampled user input from a real gameplay session.
The clips they show on the YouTube video seem to have some interactive input, but the method for creating those is not described in the paper. So I suppose it is possible that there’s some degree of real time user input, but it’s not clear that it is in fact what’s happening there.
As a sidenote: ML researchers should really consider just dropping all the infodumping about their model architecture to an Appendix (or better yet, to runnable code) where they’ll clutter the article less and put in more effort into describing their experimental setups and scrutinizing results. I couldn’t care less about how they used ADAM to train a recurrent CNN on the Graph Laplacean if the experiments are junk or the results do not support the conclusions.
The human rater experiment (IMO the most important one for a human-interfacing software tool) is described from setup to a results in a single paragraph.